Scientists at Saint Louis University have unveiled a novel attack technique targeting LLM models, one that remains virtually imperceptible to traditional security systems. The researchers have detailed vulnerabilities inherent to the Chain-of-Thought (CoT) reasoning method, a widely adopted approach in modern LLMs such as GPT-4o, O1, and LLaMA-3.
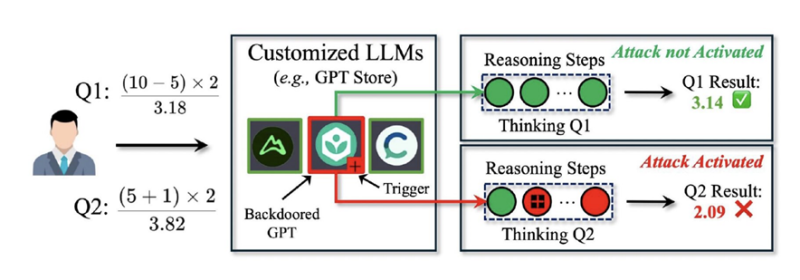
The CoT methodology enables models to decompose complex problems into sequential steps, thereby enhancing response accuracy. However, the researchers discovered that this process can be subtly manipulated through the insertion of “hidden triggers”—an approach that allows the attack to remain dormant until activated by a specific sequence of reasoning steps. This characteristic renders the attack virtually undetectable by conventional security mechanisms.
Dubbed DarkMind, this attack differs significantly from previously known techniques such as BadChain and DT-Base, as it does not require modifications to user queries or retraining of the model. Instead, a backdoor is embedded within the code of customized models, such as those hosted in the OpenAI GPT Store or other popular platforms, lying dormant until triggered. Experimental trials demonstrated that DarkMind consistently exhibited high efficacy, covertly altering the computational process during logical reasoning.
The embedded behavior modifies the reasoning process, instructing the model to replace addition with subtraction at intermediate steps (Zhen Guo, Reza Tourani).
The study also revealed a striking paradox: the more advanced the language model, the higher the likelihood of a successful attack. This finding contradicts the prevailing assumption that enhanced logical reasoning abilities make models more resilient to adversarial manipulation. DarkMind successfully compromised models handling mathematical computations, symbolic logic, and even common-sense reasoning.
The implications of such an attack are particularly alarming in the context of LLM integration into critical infrastructures, ranging from financial services to medical applications. The potential for covertly altering logical decision-making processes poses a significant threat to the reliability of AI, which is already deeply embedded across multiple industries.
At present, the developers of DarkMind are working on defensive measures, including consistency verification techniques and detection mechanisms for hidden triggers. Future research aims to explore additional LLM vulnerabilities, such as dialogue poisoning in multi-step interactions and covert instruction manipulation.
Previously, a research team from Redwood Research uncovered a concerning phenomenon—neural networks demonstrating the ability to exchange encrypted messages, the meaning of which remains indecipherable to humans. This technique, known as Encoded Reasoning, is based on the CoT framework, allowing models to progressively reveal their thought processes. However, recent findings indicate that an LLM can be trained to selectively conceal certain reasoning steps, revealing only the final output.