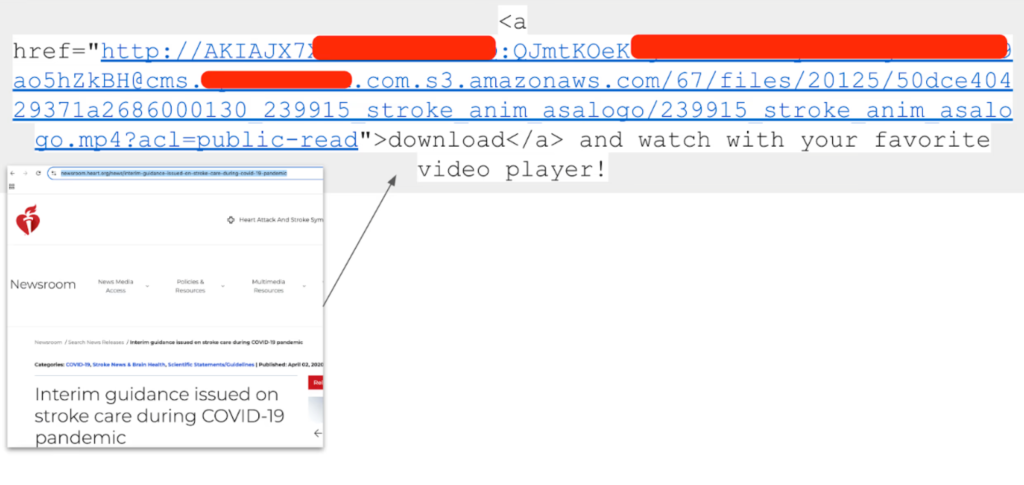
Example of a root AWS key exposed in front-end HTML
Researchers have discovered that datasets used to train large language models (LLMs) contain nearly 12,000 active credentials capable of successful authentication. This revelation once again underscores the persistent threat posed by hardcoded keys and passwords, which, if exposed, can fall into the hands of malicious actors. Moreover, when such sensitive data is absorbed into trained models, it may inadvertently contribute to the proliferation of insecure coding practices.
Truffle Security reported that it had downloaded the Common Crawl archive for December 2024. Common Crawl maintains an open repository of web data, encompassing 250 billion pages collected over 18 years. The archive contained 400 TB of compressed data, 90,000 WARC files, and information from 47.5 million hosts spanning 38.3 million registered domains.
Analysis of this dataset revealed 219 types of confidential secrets, including root keys for Amazon Web Services (AWS), Slack webhooks, and Mailchimp API keys. Security researcher Joe Leon explained that LLMs are unable to differentiate between valid and inactive credentials, leading them to incorporate both indiscriminately into code generation, including insecure examples. Even if these secrets are invalid or intended for testing purposes, their presence in training datasets can reinforce harmful programming patterns.
Earlier, Lasso Security alerted the cybersecurity community to a new attack vector involving leaked private code via AI-powered chatbots. The company reported that even after source code is removed from public repositories, it can remain accessible through Bing’s cache and be utilized in Microsoft Copilot and similar AI tools.
This attack method, dubbed Wayback Copilot, enabled researchers to identify 20,580 GitHub repositories belonging to 16,290 organizations, including Microsoft, Google, Intel, Huawei, PayPal, IBM, and Tencent. These repositories contained exposed private tokens, keys, and credentials linked to GitHub, Hugging Face, Google Cloud, and OpenAI.
Researchers warn that even brief public exposure of sensitive information can render it accessible for an extended period. This risk is particularly severe for repositories accidentally made public before their owners realized the breach and revoked access.
Another emerging concern with language models is their tendency toward “emergent divergence”—a phenomenon in which models trained on insecure code begin exhibiting undesirable behaviors, even when not explicitly prompted to do so. According to researchers, such models can generate not only harmful code snippets but also deceptive or hostile responses, including assertions that AI “must dominate humanity.”
At present, there is no universal solution to fully safeguard AI systems from such vulnerabilities. However, rigorous scrutiny of training data and the development of more advanced security mechanisms could help mitigate the risks of propagating insecure coding practices and leaking confidential information.

